How do Servers & Clients communicate
Quiz aheadNow, let's look at all this together. As part of what we saw in the previeous part, there are servers hosting resources, and clients that access the resources hosted on those servers. This relationship is made possible by a certain number of protocols put in place such as HTTP, IP, TCP, etc.
In this section, we're going to focus more on the communication between those servers and clients. This communication is what everybody initiates anytime we use the web. We can even admit that the entire web is all about client/server communication. Before we dive into this dialog, let's try to have a clearer understanding of what each one of those units is.
Server
In the previous section, I told you that a server is a computer connected to the Internet all the time and hosts resources which it serves based on a certain number of predefined rules. It's indeed. You can also recall that I made mention of some two application which could help us in setting up a folder in which to keep shared resources, and I chose the example of Apache and Nginx. Due to the function of these applications, which are serving resources, we call them servers as well. Now I guess I've just introduced another confusion. Do not panic.
The point here is that we have physical computers set as servers and computer software also set as servers. To be a server is a function, so it can be played by software or hardware. But when the two are set as a unit we will just call the whole a server. Plus, in this course, we will not focus on how they are made or even how they are really installed. Moreover, our focus will be more on the software server than the hardware. So the next time I speak of server consider that I am talking of server software and I will be specified otherwise. Nonetheless, in Chapter 3 we will see how to install server software such as Apache.
Because those servers are installed with the aim of serving web resources, they are generally called web servers. In the same analogy, we can have a database server, file sharing server, or printing server, etc.
Sometimes, when a web server is installed on a computer that is not necessarily and physically set as a server, just like your personal computer, it turns that computer into a server as well.
Client
In most countries, when you want to rent or buy a new house, you can consult a specialist(an individual or a company) who knows how and where to search for good deals. They can take you round to visit the premises and meet the landlords. They do the dirty job. You just need to sit down and they will come back and present you great places. They are called Agents. We can say that they are the clients' agents.
There are so many servers out there with countless resources in them that, It would be a heavy-duty for us to go for it each time we need. It would be better if we had an agent on the computer who could go and find the information we are looking for. Lucky you! Yes, there are agents for it. They are cool pieces of software that you can install on your personal computer or even on your mobile devices. But because we don't pay them, unlike the client's agent above, we can't call them client's agents instead we call them user agent. The reason is simply that you are a user of the computer on which they are installed, and hence their users as well.
A user agent is a special piece of software created with the ability to communicate(send and receive information) with a web server. Based on our previous understanding of the client/server relationship, this makes the user agent a client to the web server. Do you agree with me? There are many of them, and they come in a whole variety of forms. One that's particularly remarkable that almost everybody knows is the web browser. The name makes sense. The dirty work it does from one webserver to another, trying hard to find whatever resources it's asked to, is called browsing. And since it's done on the web, it inherits the name web browser. You can now see from where the name of the first web browser of Microsoft™ came from? Internet Explorer™. Throughout our quest in this book, the browser will be our main user agent to communicate with web servers.

Before we close this little talk on the client, let me make another nuance clear. Remember the confusion between server hardware and server software? the same occurs with clients. A computer on which a web client is installed is also qualified as a client. We can say that the clients are terminals, they usually play the role of middle-man between the user(either a human, a robot, or other software) and the servers.
Sometimes, the human using such terminals are also designated as the client. Thus, let me sum up the user, the computer on which a user agent is installed, and the user agent itself as the client. Henceforth, when I say client, understand I am talking of the three or just the browser.
Client/Server Communication
Now that you know what both the client and the server are, the time has come for you to dive into how they communicate.
I bracketed above that communication consists of sending and receiving information via a medium. This is the same truth for both humans and robots or software. The client and the server do the same. But there is a little change here: the server can not just send messages in the air, there must be a client to demand it before the server sends any information. The server is always stagnant waiting for any demand for information from the clients. Inversely, clients never receive a demand, they always demand it.
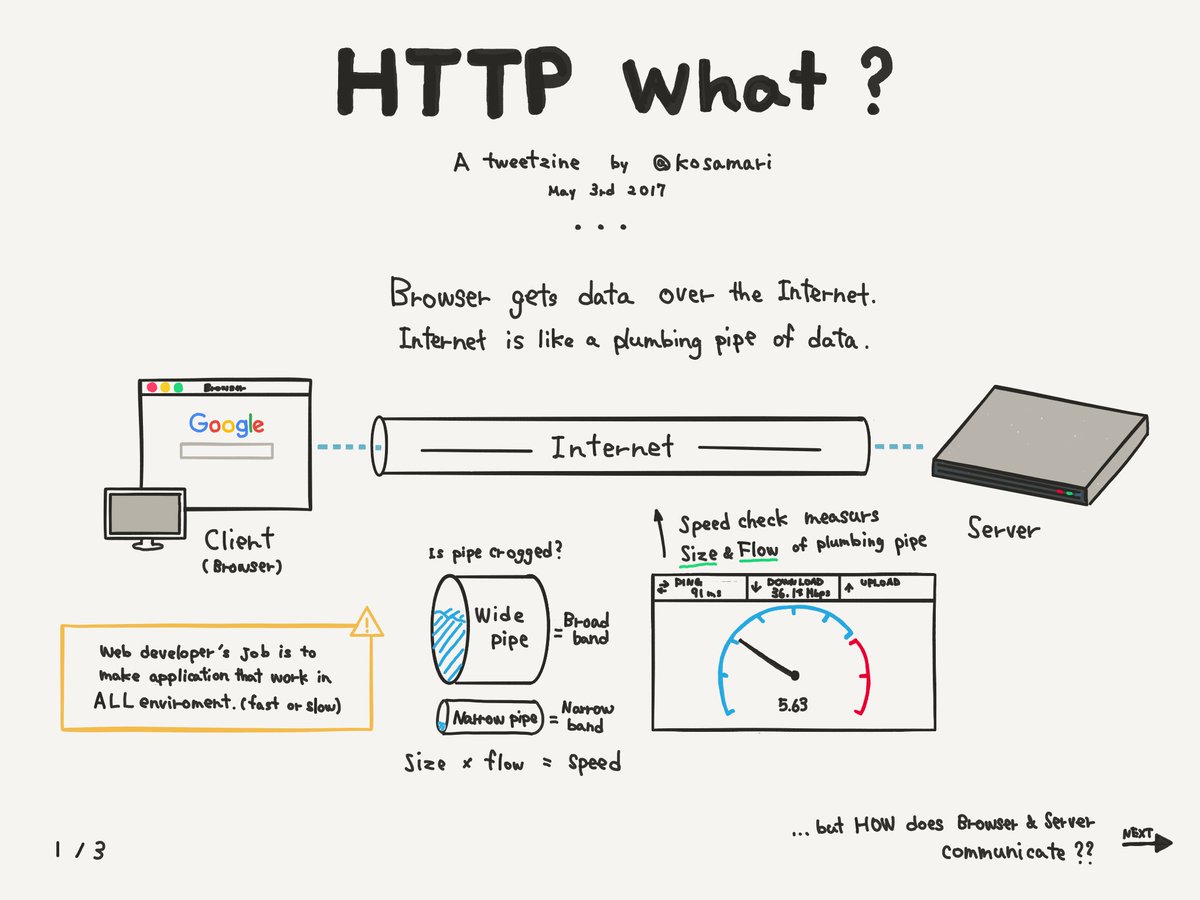
This is how it goes, the client makes a demand for a specific resource from a given server. Upon receiving the demand, that server tries its best to find the resource inside its disks. Either the server finds it or not, it will reply to the specific client who made the demand with the outcome of the job given to it. The client can decide to look at the content of the reply of just ignore it. The client can make as many demands as it wishes, the server will always try to respond. It's a good server.
For the beauty of our jargon, we will rename the client's demand a request and the server's reply a response.
a) How does the client make the request to the server?
Before we examine the client's request, it's important we understand that the client makes a request to the server targeting a specific resource. This might be a file, a folder, or even some data in a database, etc. The request might be a demand to create, update, delete, or simply to read it. So, as I said in the previous section, to target a specific resource we use a rule specified by the HTTP protocol which consists of this syntax: http protocol:Computer connected to Internet/resource.
To make the request the client does it like this http://server-address/resource. And here this might remind you how you use your web browser. Usually, in your browser's address bar, you type things like http://google.com/,https://lancecourse.com/blog`, etc. You might wonder where the server address is. It has been wonderfully replaced by a nice name like google, and phpocean. That way it will be easy for humans to read and keep it in mind than the IP address. We will come back to that topic in the next chapters.
So, to request an image called 'puppy.jpg' located in a folder called images in the server that has the name phpocean.com, the request string will look like this: http://phpocean.com/images/puppy.jpg. Then we take this string to our browser(Agent) to initiate the request. By sending the request, the browser also sends information on the computer from which the request is initiated so that the server knows where to return the response.
I also said that we need to tell the server what we want to do with the resource, either delete it, update it, or just read it, etc. The previous example is a request that demands that the server sends a copy(read) of an image so that we can view it, this type of request is called a GET request. We will see later on some other types of requests. The type of request instructs the server on how to deal with the resource. Later you will see that websites you build are full of HTTP requests, their processing, and of responses. And talking of that, what exactly is a website?
b) How does the server handle the client's requests?
How the server processes the client's request is actually complex and depends on the type of request.
Generally, the server will always try to understand the request sent to it by parsing(interpreting) the request URI. It will then do the job it was asked to do through the request. There is no static way for servers to handle requests. But, mostly, they do what most humans do when we use computers — we search for resources, we open them, we edit, we close, we delete some, we print, we send, etc.
And, this depends mostly on the type of the server. In most cases, the server will always try to find the right application required to handle the client's request. The next section goes a bit deeper on how servers, in particular the webserver, process requests from clients.
Take Quiz