The Internet is not the Web
Quiz aheadThe Internet and the Web are two names several people interchangeably use without knowing that they are actually different things. You are mixing the pedals by calling the Internet the web at one time, and the Web, the Internet at another moment. Although most at times it's done for marketing purposes or just to make things simple to explain, several people still ignore the exact difference. They still think that to access the Internet we use a Web Browser such as Google Chrome, Opera, or Mozilla Firefox. It's totally a wrong belief. Web browsers are mainly used to interact with the Web instead. But one thing is sure, the Web wouldn't exist without a network to lin on, especially a network like the Internet.
As a future web professional, it is important that you set yourself apart from that group. And there are a few reasons why I believe that. First of all, professionalism. A professional must use the right jargon of his field. And second, to allow you to know what exactly you are doing. I do not imagine you, a web developer, without knowing what exactly the Web is and what sets it apart from the Internet.
What is the Internet?
The Internet is a computer network(and a network of networks) born in the 1960s in the United States of America. Its main idea was to connect various research centers equipped with computers and facilitate the exchange of information between them. And what exactly is a network? It's a special connection made between two or more computers and/or other possible electronic devices to permit an exchange of signals(data) between them. Connecting two or more devices is like combining two or more brains to have a more sophisticated and complex brain.
Technically, there are billions of computers and other devices all around the world connected to each other through various means(cables, wireless, optical fiber). When you want to connect two computers in the same place you can use a network cable of few meters just like this:
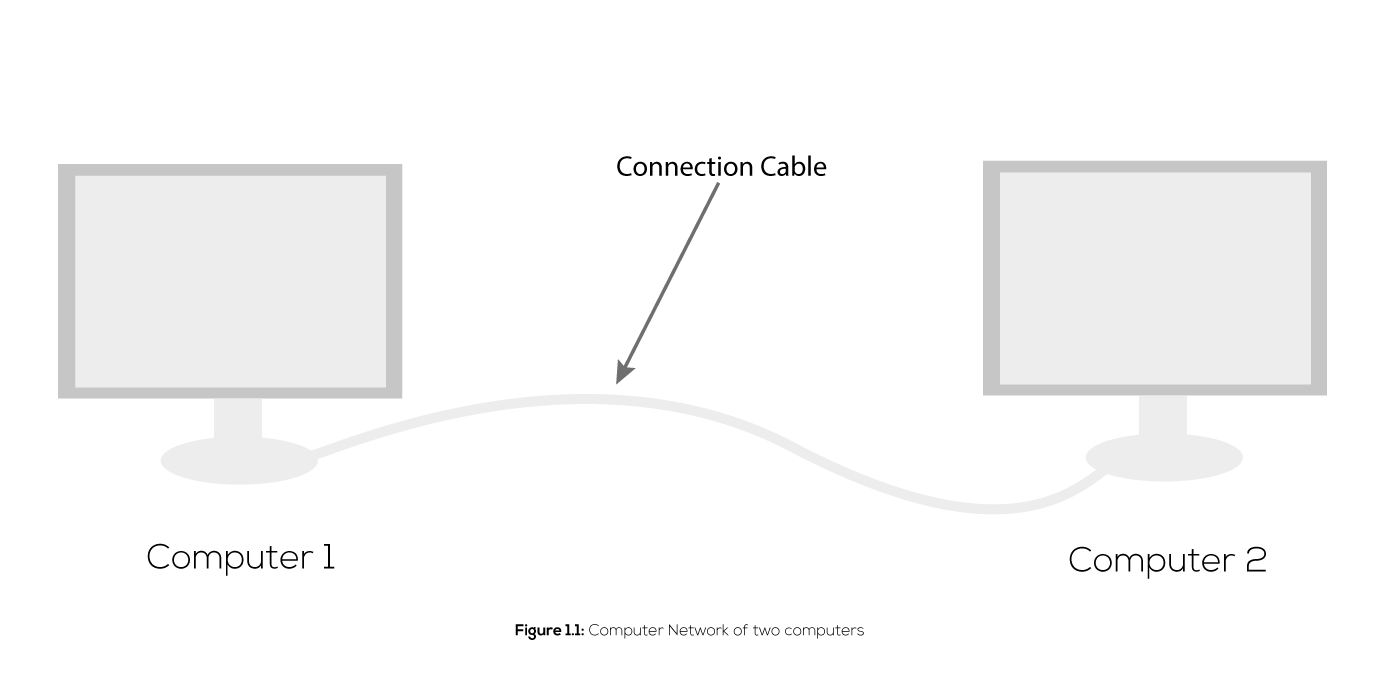
When you want to connect more than two computers you might need a switch to bridge them. With such switches, you can connect hundreds of computers in the same place. That's what you usually see in most companies.
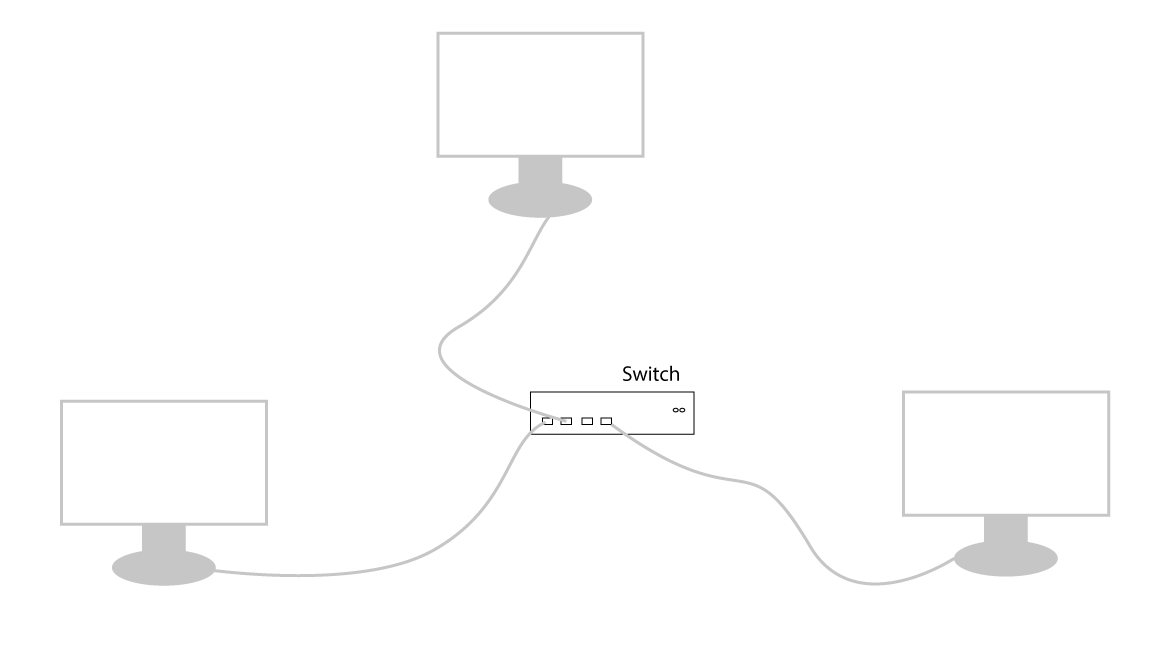
If you have such a network in your company and the company expands to a different region of your country, you might need very, very long cables to handle the connection between the offices which I am not sure you are ready to try. In that case, you can avoid cables and use a wireless system. You set up long-emitting wave signal emitters just like the ones the telecom networks use that you can see everywhere in our cities. You can end up with something like this:
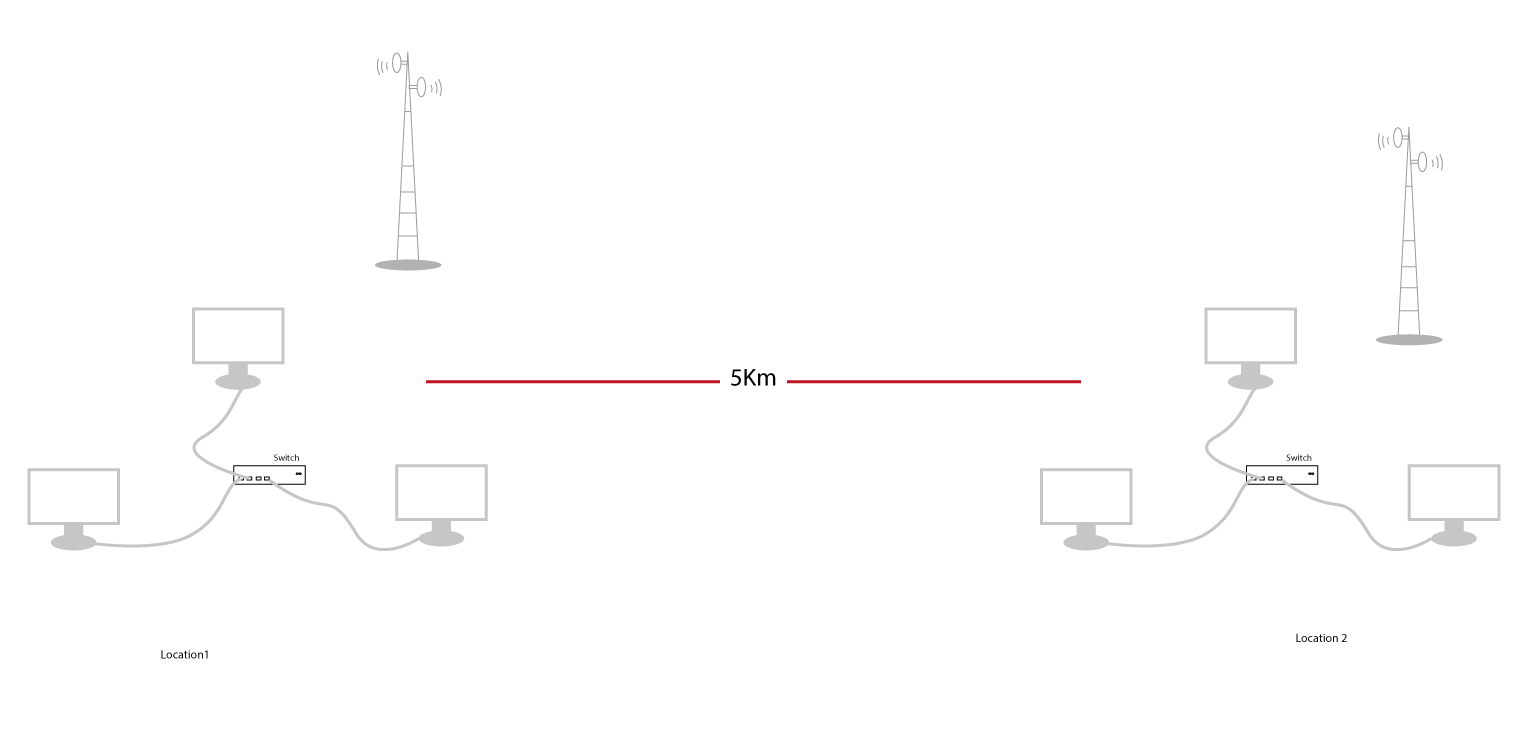
This was one of the core missions the DARPA had to accomplish and they did it well by connecting many centers such as universities and laboratories. But, note that the DARPA is in USA, how did the University College of London in England got connected to the network in the USA in November 1973? For, even the retransmission poles cannot help much because it would require millions of them to cover the distance America - Europe. Well, they used special cabling called fiber optical cable through the Atlantic ocean. That's why you can hear sometimes people calling the Internet the transatlantic data link.
Today, Internet Service Providers(ISP) plays a crucial role in establishing such connections. They say, OK, for your local networking, use your cables and little wireless connections. But, if you want your networks to connect to other networks outside, we can help you with that. And you may ask how they do so?
Well, first they set up their network in the whole country with those big antennas. It's said the network covers a country. So, wherever you are, you can connect to their network. At the same time, they use fiber-optic(green lines on the map) and satellite(Hanging on top of the planet) connections to connect to other networks in other countries and continents as shown in figure 1.4 below.
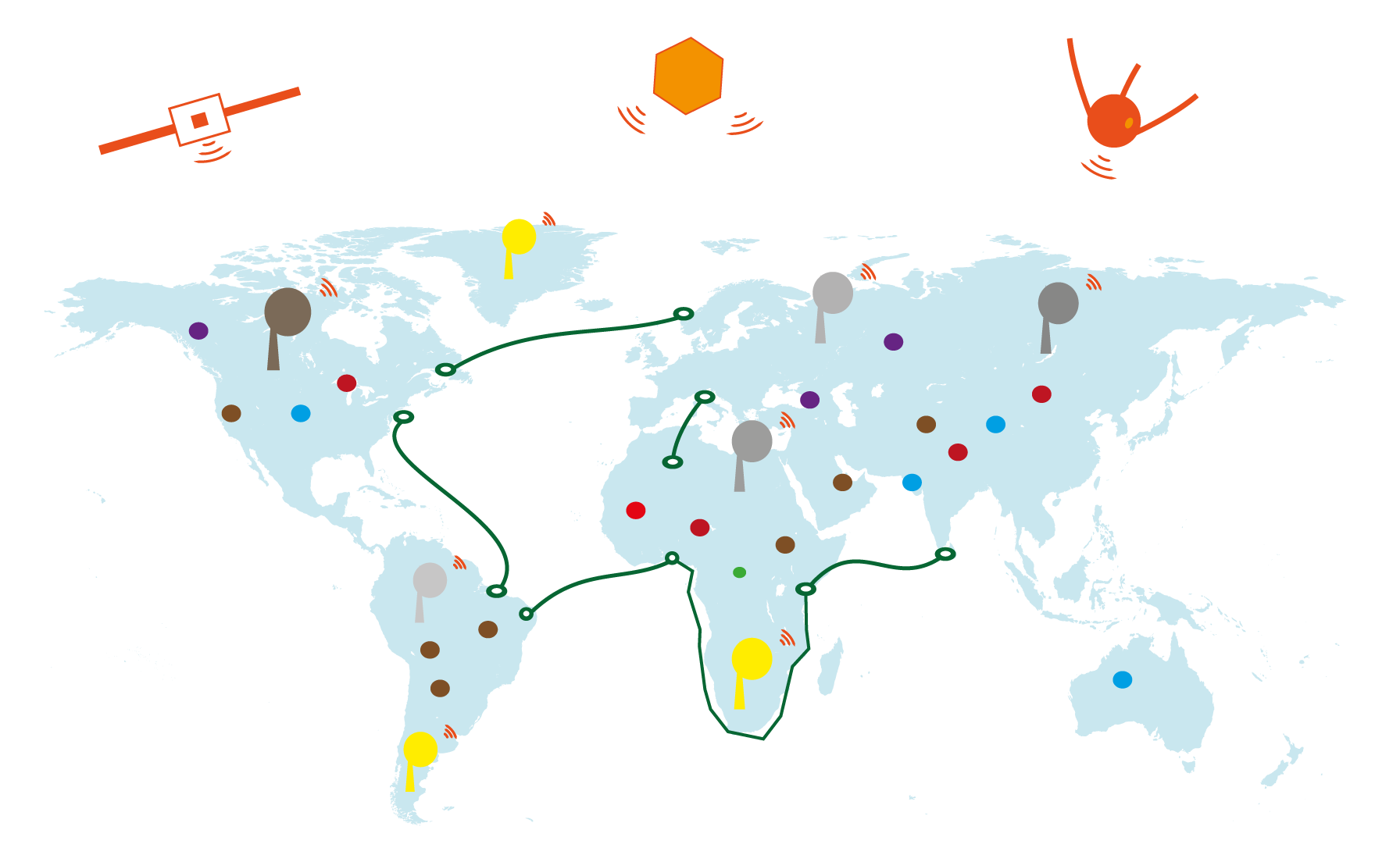
The fiber-optic network uses some special cabling that crosses the oceans, from continent to continent. When the fiber optic cable passes by or close to your country, your government or a company(like MTN) can connect to it.
The satellites are like tiny computers sent in space to remain hanging around our planet. While doing so, they can receive communication signals or send them.
So, with that set, your telecom network plays now a role of interfacing between you(actually this "you" is your computer) and the outside world, locally and internationally. To let you access the outside networks, they make of you their client and you pay a little fee to use the service. In addition, they can measure the weight of resources you download/upload through their cables, that's usually what you call your Internet bundle. But, you may wonder how they manage to connect us to those computers, how is it done, and why do we need to connect to them?
Well, let me start with the "why". Apart from increasing the brain of computing as I mentioned above, the reason why we need to inter-connect is to access some information from other people or share our own information with them. Information like news, research papers, even items to buy from China, and most importantly, to ease interaction and communication between human beings. Most often, we talk of sharing resources, because it englobes a variety of information. The Internet has the ability to allow resource sharing.
How is it done? well, it's not that easy, because imagine you are there playing a game on your computer and suddenly someone else from Russia just connects to your computer and starts to copy your family pictures and your Shakira songs. You will be like "Hey!! who the hell is this?!? That's not right!". Suddenly you unplug your computer power to prevent him from reaching your favorite Jay-z songs. And for the next few days, you will still have that sentiment of not being well protected from outside attacks. Yeah, such situations indeed are considered as a security issue. To avoid it, there are rules and conditions to determine how computers and networks can connect to others and exchange resources among themselves. Starting by physical connection rules such as the type of cables or wireless signals to use, then the type of systems of dialog(usually called protocols) to use once they are connected.
Basically, you plug a network cable to your computer or you use the Wi-Fi, and you are connected to that network. Until then, you might not have the right to access or chare any resources. Although you are connected to a network, you must authorize any access to your computer resources before anyone else can access them. You can even decide to authorize the access to only one file, an application, or a folder on your computer or LAN. If someone wants to access your computer resources, he would make a request for permission first. You have the tools to see it and decide whether to accept or not depending on the type of network you are connected to. When you agree, it means you handshake the person and you are now connected. You need to have the same permissions to access other computers' resources as well.
Now, imagine the number of possible one to one networks, company level networks, regional networks,... imagine the number of telecom networks in this world, fiber optic and satellites, all connected to each other creating a gigantic bubble of all sorts of inter-connections: that's the Internet or in short the net.
One more thing you need to know about the structure of the Internet is that each computer, or device, or a sub-network(LAN or WAN) is designated as a node. They all have a special address known as the Media Access Control(MAC) address which is used to address them. That's why sometimes you see people illustrating it like this:
What is the Web
The World Wide Web or simply the Web is a special resource sharing service established on the Internet and its protocols. It enhances the exchange of resources using the hypertext system. By analogy, understand this like having a set of books connected to each other with a rope all spread over the internet(the nodes). Basically, it takes the shape of the Internet.
You can use that rope to pull a book to you or you can follow a rope to move from one book to another. Those books are actually resources and the ropes are the (Hyper)links to/between them.
There are three aspects that are important to note in such a mechanism: the path to a resource, the location of that resource, and a way of sending a copy back of the resource to the person requesting it.
If you recall, the Internet already provides features to locate nodes(I spoke of the MAC address), well there are also some two other protocols that are important. One serves to locate the node, that's the Internet Protocol or IP and the other one helps to make the transfer of the resource, that one is the Transfer Control Protocol(TCP). The web makes extensive use of the IP system to locate computers that are "hosting" resources. Once the computers located, it's left with finding the exact resource inside the computer. To do that a system is put in place which attributes a unique path to each resource called Uniform Resource Identifier(URI). Let's quickly summarize the situation
| Locate a node on the Internet | Data transfer | Locate a specific resource in a node |
|---|---|---|
| IP | TCP | URI |
I can hear your smart brain telling you, "but my computer already identifies each resource with a unique folder path".
I know you are a genius. But, let's have a closer look at your computer file system again. You use your computer to create documents and save your pictures and videos. Your computer can help you do that because it has a memory(Hard Disk or Hard Drive) where it stores those resources. But, note that your computer is super-smart. It won't keep it anyhow, it would give you a way of organizing them so that you can easily be able to locate any piece of information you want at any moment. To do that it allows you to create some kind of drawers. Do you know you can put many things inside drawers? The exact thing is possible with the computer drawers you create. In the computer, those drawers are called folders.
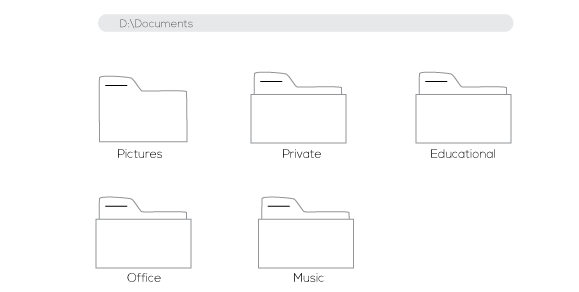
Because a computer can have more than one hard drive, to access a folder you must specify the drive on which that folder is located. Note that, generally those drives have names. If you are using Windows for example you will see names like Local Disk C, Local Disk D,... Let's assume we created a folder called Documents on the Local Disk D. To access that folder, we would open the document window and click on the disk D, then we would see our folder. We can also click on our folder to open it.
In so doing, you would notice that the computer displays the path you used to arrive at your folder. That path usually looks like this: D:/Documents.
This clearly indicates that you are in the local disk D, then you moved in a folder(drawer) called Document. If you had other folders inside the Document folder(Oh yeah! you can do that) the path might look almost the same except we will have more folders to access. If we assume we had two more folders respectively called Private and Office, we would have paths such as D:/Documents/Private and D:/Documents/Office.
Now, documents you create with your word processing software such as Microsoft Office Word, or your pictures and videos are actually the ones to contain your information. They are what we call files. They are usually different, depending on the software you used to create them. For example, if you used Microsoft Office Excel to create a sheet for your personal expenses and that you saved it in your Private folder, you would save the file as Expenses.xls. At the same time, if you had another one(an office contract) in the office folder which you used MS Word to create, might be saved under the Office folder as Contract.docx. If you bring in some pictures, you would've also noticed that some may be called birds.jpg, some grandma.png, and some songs called Waka-Waka-Cameroon.mp4, or Riyana-I-love-you.3gp, and so on.
You could notice that all those files varies in how they are named. They all have names followed by a DotSomething: .xls, .docx, .jpg, .png. All those DotSomethings are called extensions. We will come back to that latter one.
Now if we want to access any of these files we just need to follow the path leading to them like D:/Documents/Private/Expenses.xls or D:/Documents/Private/grandma.png.
These paths are actually called Links. They link us to information inside computers.

All I just mentioned happens inside each individual computer. What happens when we connect two or more computers. Well, the first thing to notice is that we are going to have more Disk space since each computer would contribute with its Local Disks. And this comes with a drawback...how to reference the local disks? Although there are many ways of handling this issue, the common idea is to have one common sharing point on each computer. That way, by connecting our computers we decide that anything each one of us wants to share should be kept in that sharing point of theirs, and they should allow others to be able to open that sharing point. By making that decision we have all agreed on the common law of interconnection. Such laws are called in computing networking protocols.
Although the Internet has ways for information sharing, the Web is notorious for information exchange and for defining specific formats of data and how they are carried. The Web has many protocols in charge of that job and one of the most prominent is the HypertText Transfer Protocol(HTTP), because it defines the laws on how we should access these resources I spoke about earlier.
In the jargon of HTTP, the files paths(links) are called URL(Uniform Resource Locator) or URI(Uniform Resource Identifier). Imagine you have a folder of your vacation pictures and short videos that you decided to share and allow other people to access. Each picture and video would have a direct path/link to only it. If someone wants to access it, it's only through that link they can get it. The general syntax of links as defined by the HTTP protocol looks like the following:
HTTP protocol:Computer connected to Internet/folder/resource.extension
Here the protocol is well HTTP. What about the computer? The computer here is the name of the computer of the person who has that picture in their hard disk. But the name here is not something like Alice or Bob. Computers are very smart, when you connect them to any network like the Internet, they automatically get themselves some funny names. Those names usually look like this: 192.168.0.5. Funny name right? Yes, they know we will laugh at them, so they don't call it a name, instead, they call it an IP Address. This principle of naming themselves is one of the Internet's protocols as I mentioned earlier, and the Web uses it to its benefit.
So, our link would look like this now: http:192.168.0.5/folder/resource.extension.
But now you might ask how the computer knows in which disk of the sharer to go and fetch that resource. Remember the sharing point I spoke about above? The HTTP protocols have rules on where to set it, and there is even a general name to that folder: web root. So all computers using the HTTP protocol know where it is set. And, there is also usually a special software installed on computers that wish to share their resources through the HTTP protocol and it's called HTTP Server. Some examples are Apache and Nginx. The name sounds right, it serves files to people who need them through the HTTP protocol, perhaps HTTP Clients?(eg. the web browser). We will discuss further on that later in this book.
This technique allows us to access the information we need without digging too much. Unlike books where you have to go through several pages before accessing a specific page, the Web's URLs allow us to jump from one resource to another without going through the previous ones. For example, you can't jump to page 85 of a book without flipping preview pages, if you start from the beginning, or without flipping the down pages if you start from the end. In the case of Web Documents, like this website, you can jump to the contact page, or any other page without having to browse the home page or the table of content. This type of link is called Hyperlink, and the text(content inside) inside documents is called Hyper Text. Now the acronym HTTP(HyperText Transfer Protocol) makes sense.
Thus far, we have discovered the main technologies that make up the World Wide Web:
- Special computers, located on the Internet by their IP address, to host resources and make them available all the time called servers
- Special software(Application Server like Apache) to define where shared data on a server is kept(webroot) and to serve them when they're requested
- Uniform Resource Identifier(URI), which gives a unique identifier for each resource on the servers
- The HyperText Transfer Protocol(HTTP), defining how we request for, or send a resource of HyperText type
- URL to used as HyperLinks to interconnect resources on the Internet
- TCP as a support protocol to help in carrying resources in conjunction with HTTP
- Hypert Text format to define how resources are formated before transportation.
You realize now that the Web is a set of technologies. It's not a special set of installation. It even used technologies that were in existence. The particularity of the Web, as I mentioned earlier, is to define a way of sharing resources over the Internet, make sure the right formats are defines so that many more types of information can be used on the Internet, and finally, assure good transportation of resource.
In order to establish the relative autonomy of the Web as a subject matter, we recount its origins and so its relationship to other projects, both intellectual such as Engelbart’s Human Augmentation Project, as well as more purely technical projects such as the Internet -H. Halpin, Social Semantics: The Search for Meaning on the Web
So, the web is a set of networking technologies and protocols defined to favor easy and agreeable exchanges of the various formats of resources over the Internet network. Primarily the exchange of those resources is done between servers, that host the resources, and clients, that are used to demand resources and who are in charge of getting a better way to present it to the human. It's almost impossible to describe the web without associating it with other technologies on which it relays such as the Internet.
Somehow, the web is just a small part of the Internet.
In the next section, we will see in toto how that server-client communication is done and why it's important you understand it as a web developer.
But before, let's see another analogy on the affinity between the Web and the Internet. I will use the telephony analogy to explain it.
When you buy a telephone you need a SIM card to have access to the telecom network. The phone is like your computer and the SIM card like your Modem. The number you are automatically attributed is the IP address.
The SIM establishes a relation(a connection) between your phone and your telecom network. In that case, we speak of being connected to the network.
Even if you are not doing anything yet with the phone, you are connected to the network. That's why there is a network signal on the phone to show how strong or weak is that connection. This is the same as being connected to the Internet.
Once connected, you can use services like voice call, SMS, or even applications like Whatsapp or twitter over the network. In the same way, you can transfer files, make a voice call, or browse websites( Wink! here comes the Web) over the network. Do you remember that your telecom networks too are connected to that Giga network? You can see that.
The Web is just a service over a network, just like voice calls, or SMSes.
It is a bit tricky to notice the difference between a voice call, SMS, and other things you can do with your phone, and the telecom network itself. It's the same that occurred with the Web, as an application on the Internet network. Maybe one day you will be able to use the Internet, combine it with the Web, and other ideas to create a new way of communication just like the VoIP.
Take Quiz